|
|
|
|
|
|
|
|
|
|
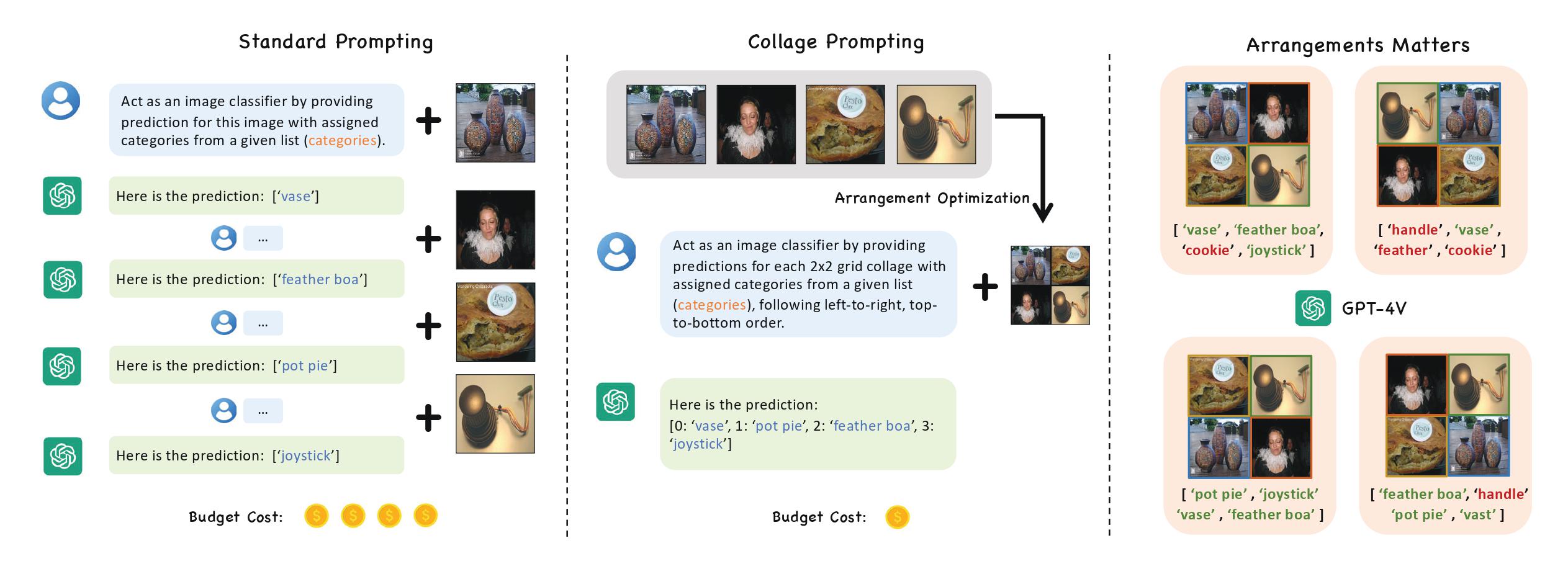
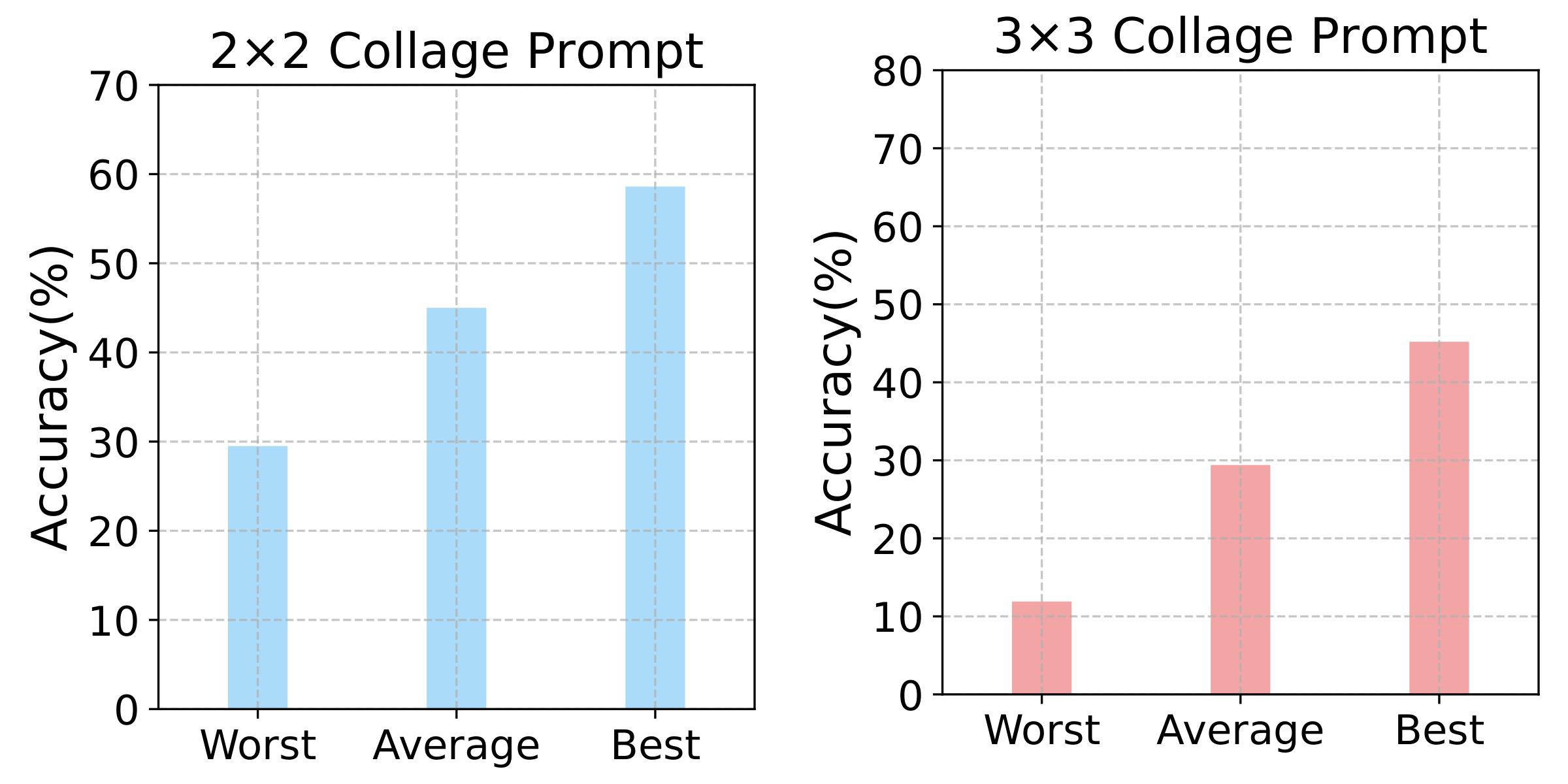
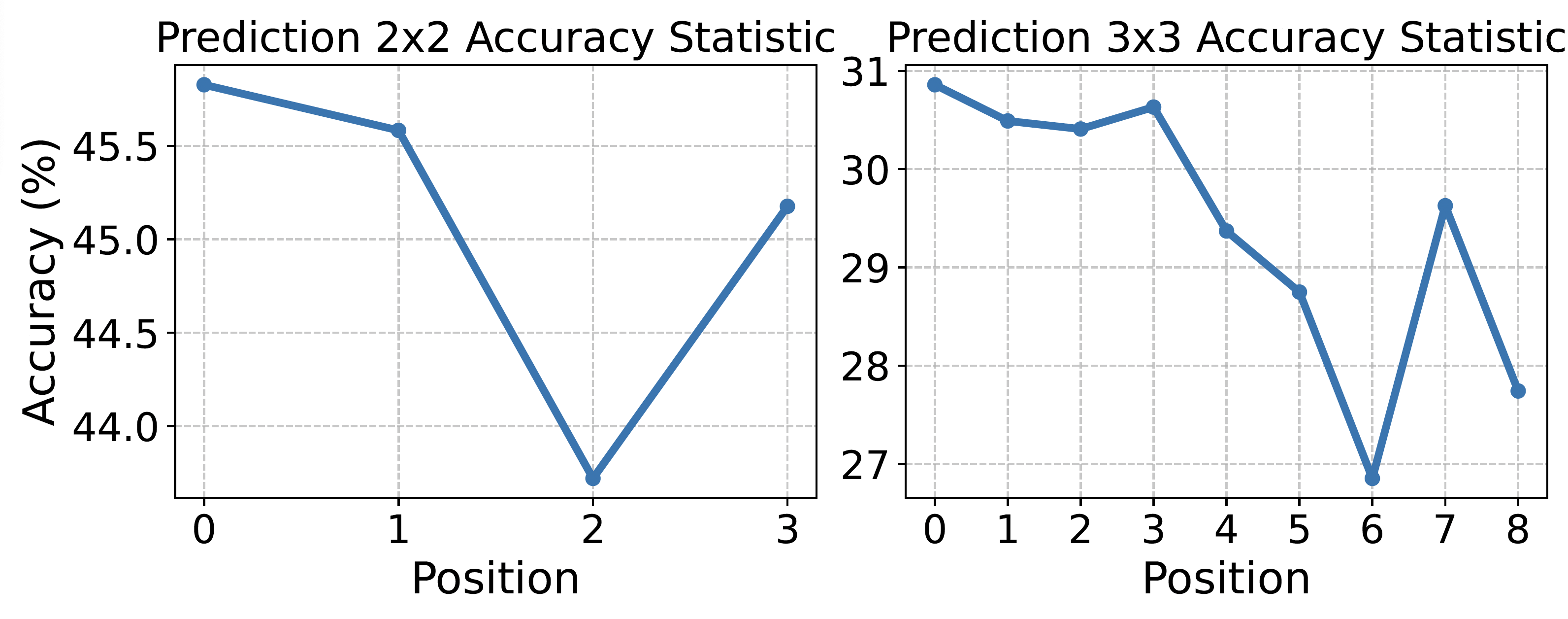
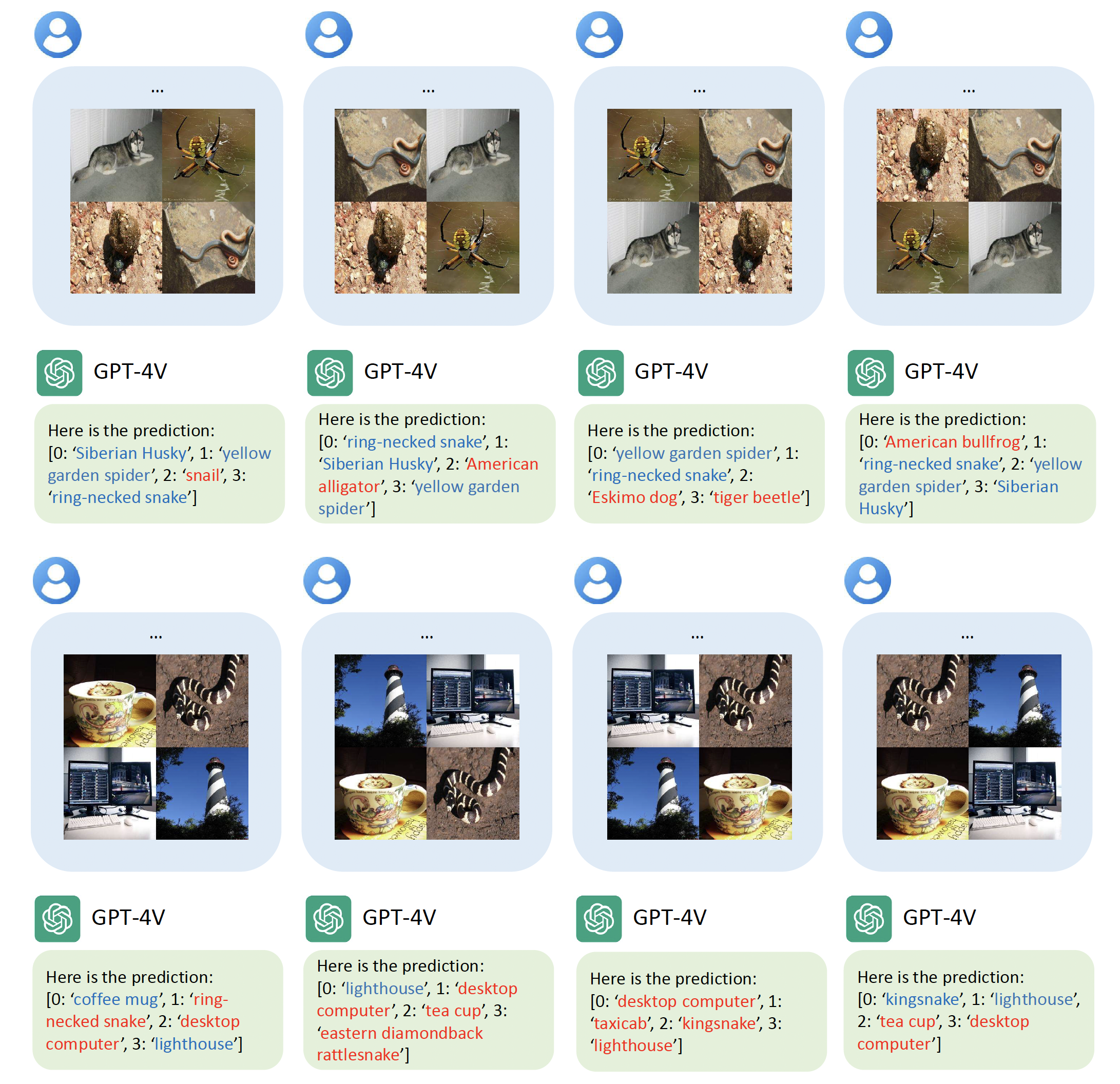
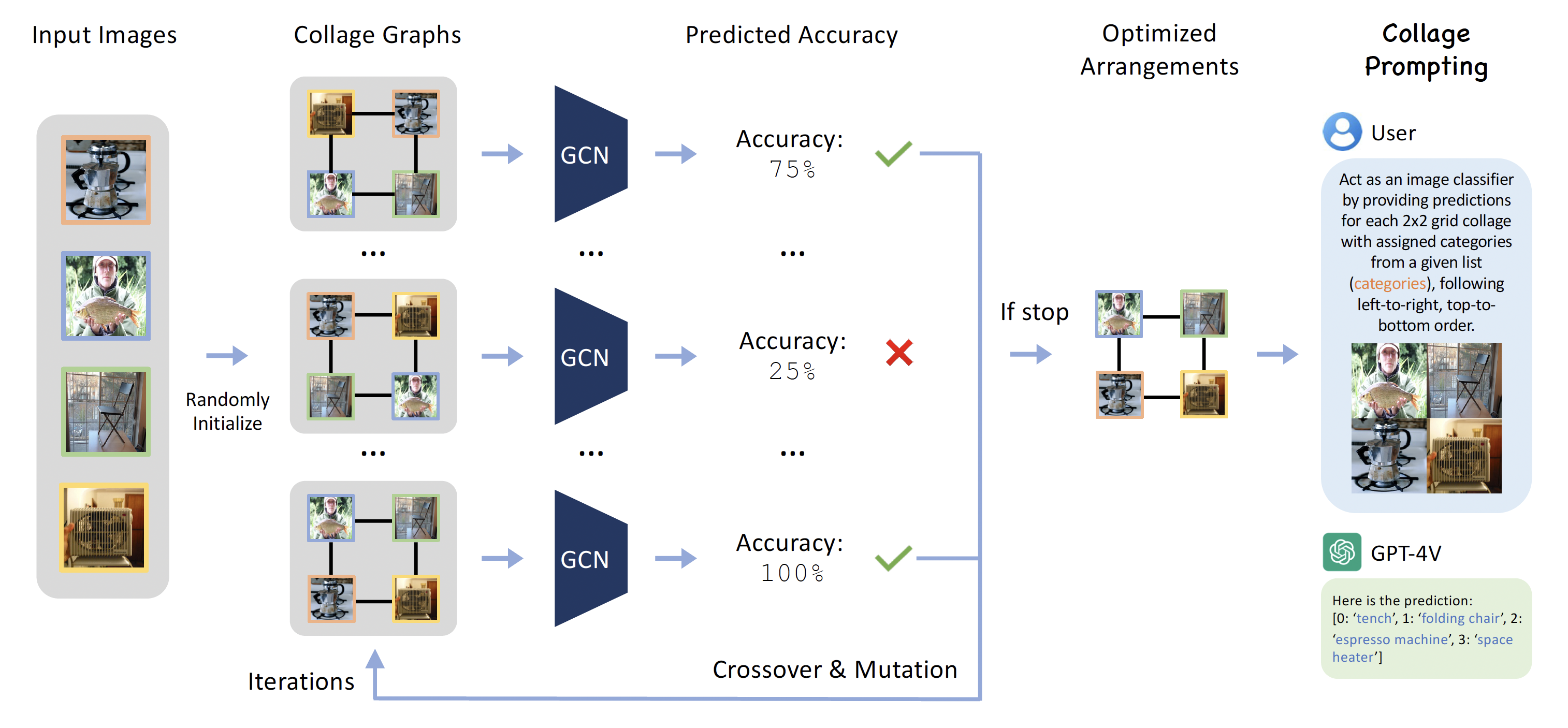
Recent advancements in generative AI have suggested that by taking visual prompts, GPT-4V can demonstrate significant proficiency in visual recognition tasks. Despite its impressive capabilities, the financial cost associated with GPT-4V's inference presents a substantial barrier to its wide use. To address this challenge, we propose a budget-friendly collage prompting task that collages multiple images into a single visual prompt and makes GPT-4V perform visual recognition on several images simultaneously, thereby reducing the cost. We collect a dataset of various collage prompts to assess its performance in GPT-4V's visual recognition. Our evaluations reveal several key findings: 1) Recognition accuracy varies with different positions in the collage. 2) Grouping images of the same category together leads to better visual recognition results. 3) Incorrect labels often come from adjacent images. These findings highlight the importance of image arrangement within collage prompt. To this end, we construct a benchmark called CollagePrompt, which offers a platform for designing collage prompt to achieve more cost-effective visual recognition with GPT-4V. A baseline method derived from genetic algorithms to optimize collage layouts is proposed and two metrics are introduced to measure the efficiency of the optimized collage prompt. Our benchmark enables researchers to better optimize collage prompts, thus making GPT-4V more cost-effective in visual recognition.
|
|
 |
 |
|
|
 |
|
|
 |
|
|
|
|
|
 |
|
|
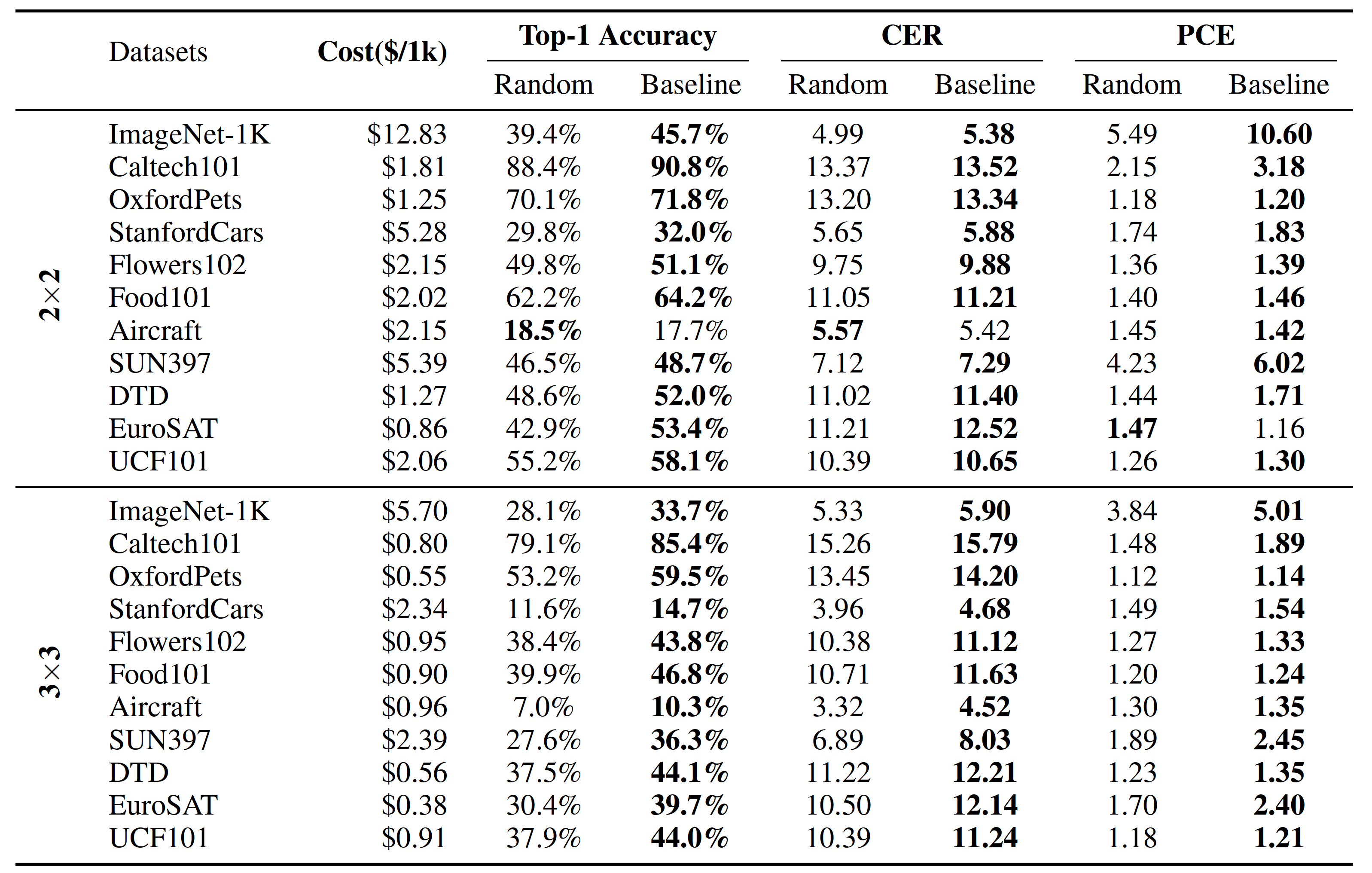
This baseline serves as a starting point for further research and optimization, providing a clear pathway to enhancing the cost-efficiency of visual recognition tasks using GPT-4V. The experimental results demonstrate significant improvements in recognition accuracy when using optimized collage prompts compared to random arrangements.
Related and Concurrent WorkCheng, Z., Kasai, J., & Yu, T. Batch prompting: Efficient inference with large language model apis. In EMNLP, 2023. [PDF] [Website] Lin, J., Diesendruck, M., Du, L., & Abraham, R. BatchPrompt: Accomplish more with less. In ICLR, 2024. [PDF] Anonymous. Tune-n-Batch: Fine-Tuning LLMs for Batch Prompting. In ACL submission, 2024. [PDF] Yue, M., Zhao, J., Zhang, M., Du, L., & Yao, Z. Large language model cascades with mixture of thoughts representations for cost-efficient reasoning. In ICLR, 2024. [PDF] [Website] Wu, W., Yao, H., Zhang, M., Song, Y., Ouyang, W., & Wang, J. GPT4Vis: what can GPT-4 do for zero-shot visual recognition?. In arXiv, 2023. [PDF] [Website] Jiang, Y., Irvin, J., Wang, J. H., Chaudhry, M. A., Chen, J. H., & Ng, A. Y. Many-Shot In-Context Learning in Multimodal Foundation Models. In Arxiv, 2024. [PDF] [Website] |
Acknowledgements |